At DocRouter.AI, we build an AI app for processing documents using LLMs. As our user base grew, we needed a reliable way to handle billing for self-serve customers. This post explains our Stripe integration, focusing on key design choices. We’ll cover why we chose Stripe, how we keep things flexible, pricing decisions, APIs used, and more.
Table of Contents
- Why Use Stripe?
- How Stripe Payments Get Handled
- SPU Credits
- Pricing Strategy For AI Products
- DocRouter.AI Software Stack
- Free Tier, Plans, and A-La-Carte Credits
- Prices for Large vs. Small Customers
- Price Changing Flexibility
- Environment Variables
- The Stripe Product and Price Metadata
- Python APIs for Retrieving Products and Prices
- Stripe Checkout and Billing Portal
- Webhooks and Synchronization
- MongoDB Schema
- Tracking SPU Usage
- Development and Testing with Stripe
- Need Help with Your Pricing Strategy?
Why Use Stripe?
Stripe handles the credit card transactions, and handles global currencies/taxes. For an AI app with variable usage, it’s essential — manual billing would be error-prone and slow. Companies using Stripe don’t need to deal with credit cards. They only need to identify the customers by a unique customer ID managed by Stripe.
How Stripe Payments Get Handled
Stripe supports:
- subscriptions for recurring plans
- one-time charges for credits,
- webhooks for real-time updates.
It also supports metered charges, but we will not use the Stripe implementation for meters. It is more convenient to implement our own metered support, keeping track on our platform of usage, and charge through Stripe the monthly cost.
SPU Credits
On DocRouter.AI, customers purchase credits called SPUs (Service Processing Units) - this is our abstraction for document page processing, and for LLM token use. Many other SAAS companies use a credit-purchase based mechanism. For example, Databricks measures credits as DBUs (Databricks Processing Units), and charges hourly cluster usage a number of DBUs that depends on the cluster size.
As long as the credit units are tied to predictable units of operation - for example, number of pages processed in a document - a credit purchase mechanism is a good choice.
Pricing Strategy For AI Products
When setting up pricing through Stripe, you have to be strategic. You need to cover the needs of Enterprise customers, but also small companies and occasional users. Some customers prefer to purchase credits a-la-carte, while others prefer the predictability of a monthly subscription.
Pricing must be tailored to all types of customers you have at the current stage - and, has to be as simple as possible.
The diagram below describes different pricing strategies practiced in the industry:
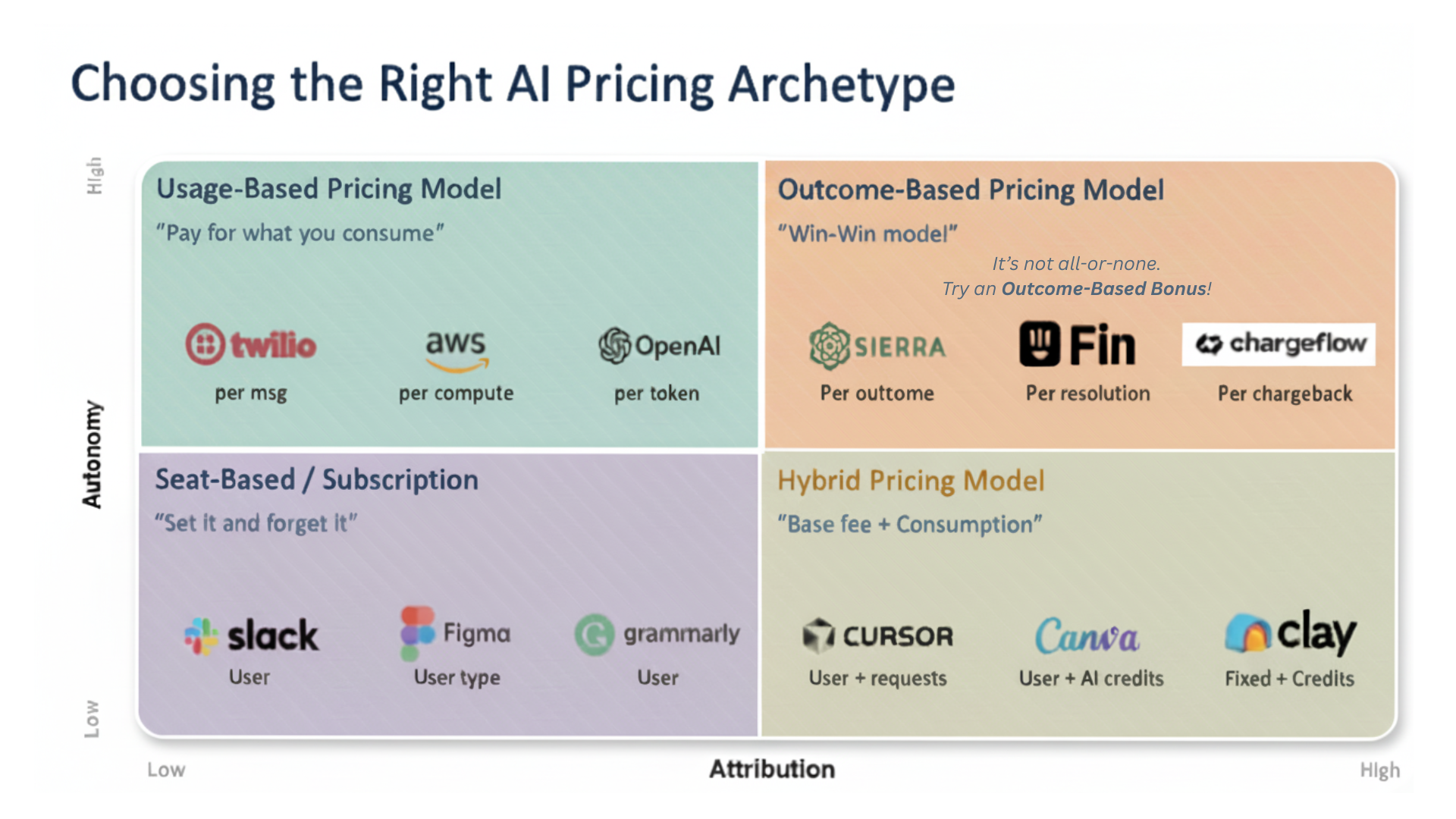
Ideally, products would be priced with an Outcome-Base Model (top right quadrant). This works well if a business is vertical in an industry, and if product value has high attribution.
DocRouter.AI is a horizontal, data-layer product - and uses a Hybrid Pricing Model based on monthly subscriptions and/or a-la-carte SPU credit purchases.
DocRouter.AI Software Stack
- The DocRouter.AI front end is Next.JS, with Next.Auth user authentication
- The back end is Fast API
- Our database is MongoDB
DocRouter supports agentic Claude Code integration and MCP, allowing document workflows to be controlled through a simple chat interface.
Users control all DocRouter.AI functions either through the UI, or through REST APIs, using access tokens. A Python SDK and a Typescript SDK are available.
Having the flexibility to control DocRouter programmatically, either through agentic interfacing, or through APIs is great.
However, use tracking (aka metered billing) has to be automated, and the customer needs to be charged a small percentage above the underlying cost charged by LLM and cloud providers.
Stripe integration is, thus, an essential ingredient in making this kind of programmatic integration possible.
Free Tier, Plans, and A-La-Carte Credits
When you are starting, the best pricing is a simple one that your customer understands - especially for self-onboaded customers.
For DocRouter, we want users to start free, upgrade to plans, and be able to buy extra credits without friction. Here’s how we did it:
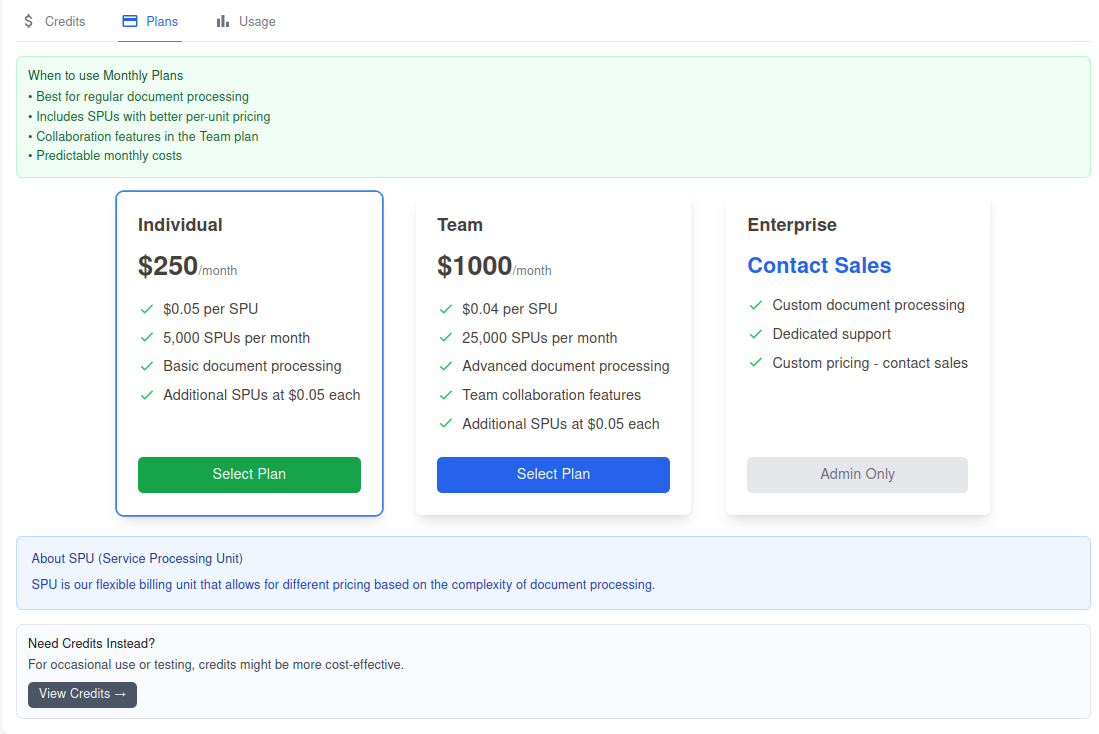
New orgs get 100 granted SPUs (no card needed). Additional credits can be purchased. Users can subscribe to an Individual or Team plan, at a discount over the a-la-carte credits price. Or, they can select the Enterprise plan, which is invoiced outside of Stripe where we can charge based on the customer outcomes (aka outcomes-based pricing).
Prices for large vs. small customers
The business challenge here is for the pricing scheme to be flexible enough to accommodate large enterprise usage, at custom prices - while also allowing self-onboarded customers.
Consumption waterfall: allowance first, then purchased, then granted. Keeps costs low for light users, upsell for heavy ones.
The prices need to be in line with what is usually charged for document AI processing - while also capturing the value of more advanced, custom document workflows.
Price changing flexibility
The engineering challenge is, on the other hand, in how to create this pricing structure in Stripe, and ensure the variable part of the config (amounts, utilization thresholds) resides in Stripe configuration rather than local DocRouter.AI code.
Updating amounts or utilization thresholds at a later time should not require coding changes in DocRouter.AI. These updates should be possible by merely chaging price configuration in Stripe.
Pricing updates, however, does not impact existing customers (aka grandfathering).
How does it all work?
Environment Variables
Three Stripe-related environment variables are configured for integration:
STRIPE_SECRET_KEY - Your Stripe API key for authentication. Required to enable Stripe integration.
STRIPE_WEBHOOK_SECRET - Secret for verifying webhook signatures. The DocRouter.AI webhook is called by Stripe when various events happen: a user started or stopped a subscription, or purchased a-la-carte SPU credits.
STRIPE_PRODUCT_TAG - The product identifier in metadata (default: "doc_router"). Allows filtering prices to find only those belonging to your product.
If STRIPE_SECRET_KEY is not set, Stripe integration is disabled and DocRouter operates in local-only mode.
The Stripe Product and Price metadata
Stripe uses the following ‘objects’: Products, Prices (multiple per product), Users (one per customer), and Subscriptions (each with one or more Prices.
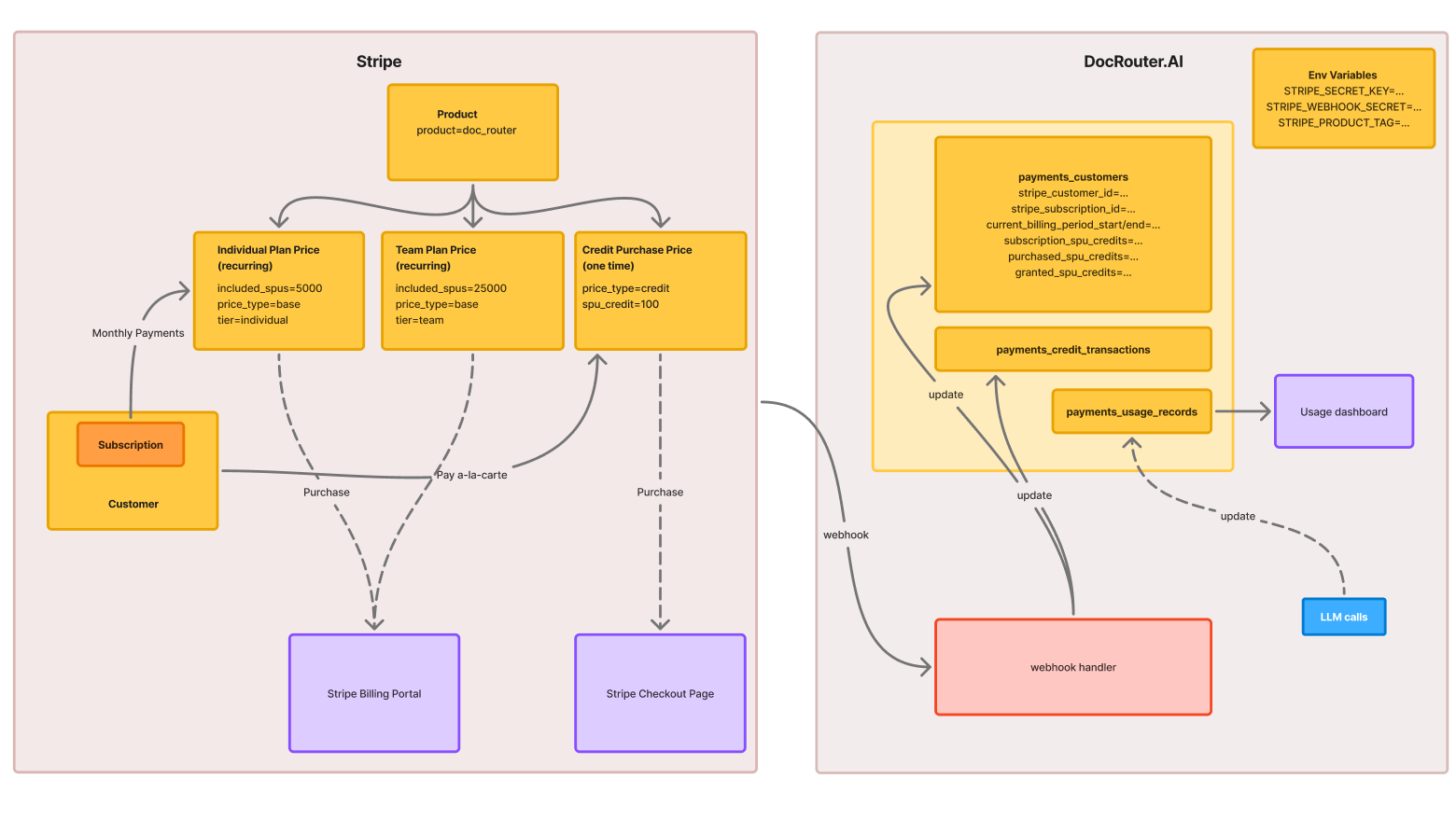
We could identify the Products and the Prices by stripe IDs saved as environment variables, similar to how we use the STRIPE_SECRET_KEY. However, that is not an advantageous way to set things up.
Instead, we detect Products and Prices by reading their metadata in Stripe, and filtering for the Products and Prices configured for our company.
This way, a single Stripe account can be used as an umbrella for potentially multiple products, allowing for future extensibility.
-
We create a Stripe DocRouter Product

-
And we assign it a
product=doc_routerkey/value in the price metadata. The DocRouter.AI software detects the product using the Stripe Python API, filtering all products to find specifically the one with this key/value.
-
We create two recurring Prices we’ll use for monthly subscriptions: the Individual Price, and the Team Price. We again use metadata to auto-detect the prices:
- The Individual Price has metadata included_spus=5000, price_type=base, tier=individual.
- The Team Price has included_spus=25000, price_type=base, tier=team
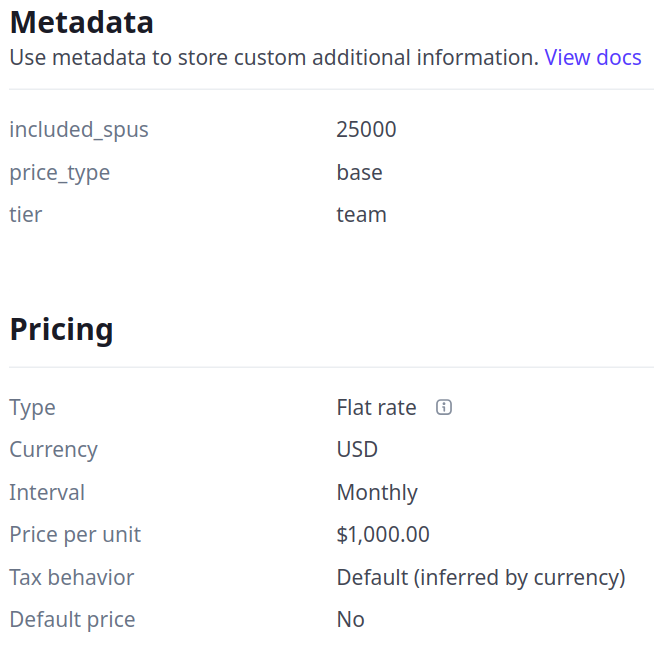
The DocRouter.AI detects the prices and the tier limits from the metadata.
Python APIs for Retrieving Products and Prices
DocRouter.AI uses the Stripe Python SDK to dynamically fetch pricing configuration at startup. The complete implementation can be found in our payments.py file. Here’s how the key parts work:
Retrieving All Prices with Product Data
prices = stripe.Price.list(active=True, expand=['data.product'])
The expand=['data.product'] parameter loads the full product object (including metadata) alongside each price in a single API call.
Filtering by Product Metadata
product_prices = [
price for price in prices.data
if price.product.metadata.get('product') == 'doc_router'
]
This filters prices to only those belonging to our DocRouter product.
Parsing Price Metadata
for price in product_prices:
metadata = price.metadata
price_type = metadata.get('price_type')
if price_type == 'base':
tier = metadata.get('tier')
included_spus = metadata.get('included_spus')
# Store tier limits for subscription plans
All pricing configuration lives in Stripe—we can update prices and tier limits without code changes.
Wrapping Stripe APIs for Async
Since DocRouter.AI uses FastAPI (an async framework), we wrap Stripe’s synchronous API calls to run in a thread pool:
async def _run_in_threadpool(func, *args, **kwargs):
loop = asyncio.get_event_loop()
return await loop.run_in_executor(None, partial(func, *args, **kwargs))
This prevents blocking the event loop. In practice, we call:
prices = await _run_in_threadpool(
stripe.Price.list,
active=True,
expand=['data.product']
)
The wrapper runs the synchronous stripe.Price.list() in a separate thread, keeping our async FastAPI endpoints responsive.
Stripe Checkout and Billing Portal
Purchasing Credits
When users buy a-la-carte credits, we create a Stripe Checkout session:
session = stripe.checkout.Session.create(
customer=stripe_customer_id,
payment_method_types=['card'],
line_items=[{...}],
success_url=success_url,
cancel_url=cancel_url,
metadata={'org_id': org_id, 'credits': credits}
)
Users are redirected to Stripe’s hosted checkout page—we never see their credit card details. Stripe handles all payment security.
Managing Subscriptions
For subscription management, we use Stripe’s Billing Portal:
session = stripe.billing_portal.Session.create(
customer=stripe_customer_id,
return_url=return_url
)
The portal lets users update payment methods, view invoices, and cancel subscriptions—all handled by Stripe.
Webhooks and Synchronization
Stripe sends webhooks for important events. We verify and process them:
event = stripe.Webhook.construct_event(
payload,
signature_header,
webhook_secret
)
Key events we handle:
checkout.session.completed- Add purchased creditscustomer.subscription.updated- Sync subscription changescustomer.subscription.deleted- Clear subscription datainvoice.payment_succeeded- Record successful payments
To prevent double-crediting, we track processed transactions in the db.payments_credit_transactions collection.
On startup and via webhooks, we sync Stripe data to MongoDB. This keeps local data fresh without constant API calls.
MongoDB Schema
We store payment data in MongoDB collections:
payments_customers - One document per organization:
{
org_id: "...",
user_id: "...",
stripe_customer_id: "cus_...",
user_name: "...",
user_email: "...",
// Subscription fields
subscription_type: "individual" | "team" | "enterprise",
subscription_spu_allowance: 5000,
subscription_spus_used: 1234, // Reset each billing period
stripe_subscription_id: "sub_...",
stripe_subscription_item_id: "si_...",
stripe_subscription_status: "active",
stripe_current_billing_period_start: 1234567890,
stripe_current_billing_period_end: 1237246290,
// Credit fields
purchased_credits: 10000,
purchased_credits_used: 5000,
granted_credits: 100,
granted_credits_used: 50,
// Metadata
created_at: ISODate(...),
updated_at: ISODate(...),
subscription_updated_at: ISODate(...)
}
Subscription SPU usage (subscription_spus_used) is atomically reset each billing period. Subscription allowances renew monthly. Purchased and granted credits persist until consumed.
payments_credit_transactions - Audit trail for credit purchases:
{
session_id: "cs_...",
org_id: "...",
credits: 1000,
processed_at: ISODate(...)
}
payments_usage_records - Log of all SPU usage:
{
org_id: "...",
spus: 42,
operation: "document_processing",
source: "backend",
timestamp: ISODate(...),
llm_provider: "anthropic",
llm_model: "claude-3-5-sonnet-20241022",
prompt_tokens: 1234,
completion_tokens: 567,
total_tokens: 1801,
actual_cost: 0.023
}
Tracking SPU Usage
When LLM calls are made, we increment SPU usage:
async def record_payment_usage(org_id, spus):
# Consumption order: subscription → purchased → granted
balances = await get_current_balances(db, org_id)
consumption = calculate_consumption_breakdown(spus, balances)
# Update balances atomically
await update_customer_balances(db, customer_id, consumption)
# Save usage record
await save_complete_usage_record(db, org_id, spus, consumption)
The consumption waterfall ensures subscription credits are used first, then purchased, then granted.
Users view their credit utilization on the usage page. All data comes from MongoDB — no Stripe API calls needed to track usage, keeping the UI fast.
Development and Testing with Stripe
Stripe provides separate test and production environments. During development, we use test mode keys:
# .env for development
STRIPE_SECRET_KEY=sk_test_...
STRIPE_WEBHOOK_SECRET=whsec_...
STRIPE_PRODUCT_TAG=doc_router
Test mode keys (sk_test_*) access a completely separate sandbox with its own customers, subscriptions, and products. You can:
- Create test products and prices in the Stripe Dashboard
- Use test credit cards (like
4242 4242 4242 4242) for checkout - Trigger webhooks manually to test event handling
- View all transactions without affecting production data
For production, swap to live keys (sk_live_*). The same code works in both modes—Stripe automatically routes API calls to the correct environment based on the key prefix.
This separation lets us develop and debug payment flows safely without risking real customer data or charges.
Need Help with Your Pricing Strategy?
Take what you are thinking and try 10x that price for a fixed price. If they say yes, everyone is happy. If they say no, you can talk about fair pricing for the value you are providing for their business (aka Outcome-based pricing) typically aligned of a cost/revenue metric that matters a lot to your customer.
If you’re implementing your own pricing strategy and need expert advice, Randy Carlton offers consultation on pricing for AI and SaaS businesses.
Get Pricing Strategy Advice
Book a 30-minute consultation with Randy Carlton to discuss your pricing challenges and get expert guidance on implementing effective pricing strategies for your AI business.