This is a post about Python programming for the web back end. (Cross posted from LinkedIn.)
FastAPI Background Jobs Needed
I needed my FastAPI backend to spawn background jobs, for example, to run Optical Character Recognition (OCR), Named Entity Recognition (NER), or Large Language Model (LLM) orchestration. The FastAPI ran as an Api service to a NextJS front end React application.
The details of the front end don’t matter here. But, importantly, the system uses a MongoDB database back end.
My question was – what were the options available, in this case, for architecting the background jobs?
- These jobs could take anywhere between a few seconds and a minute to complete.
- Load varies. Jobs can stay idle a while, then ramp up and have to handle load at scale, sometimes with hundreds of requests in parallel.
Queues implemented on top of MongoDB
My plan was to implement a queue system in MongoDB, so I can post requests for background work to the queue from FastAPI, when a REST API is called. Whether I used a background thread, or background process, the plan was to read the work request from the queue, and process it.
Two options became available, and the purpose of this post is to describe them in a bit of detail:
- Background handled as Coroutines in the FastAPI. This should handle the require scale when, later, I will need distribute the FastAPI across multiple processes, deployed to ECS or Kubernetes.
- Separate background process.This should support multiple processes scaled up and down part of a process pool.
Option 1: Background Jobs as Coroutines in FastAPI
This approach involves using asynchronous programming within your FastAPI application to handle background tasks. Here are the key points:
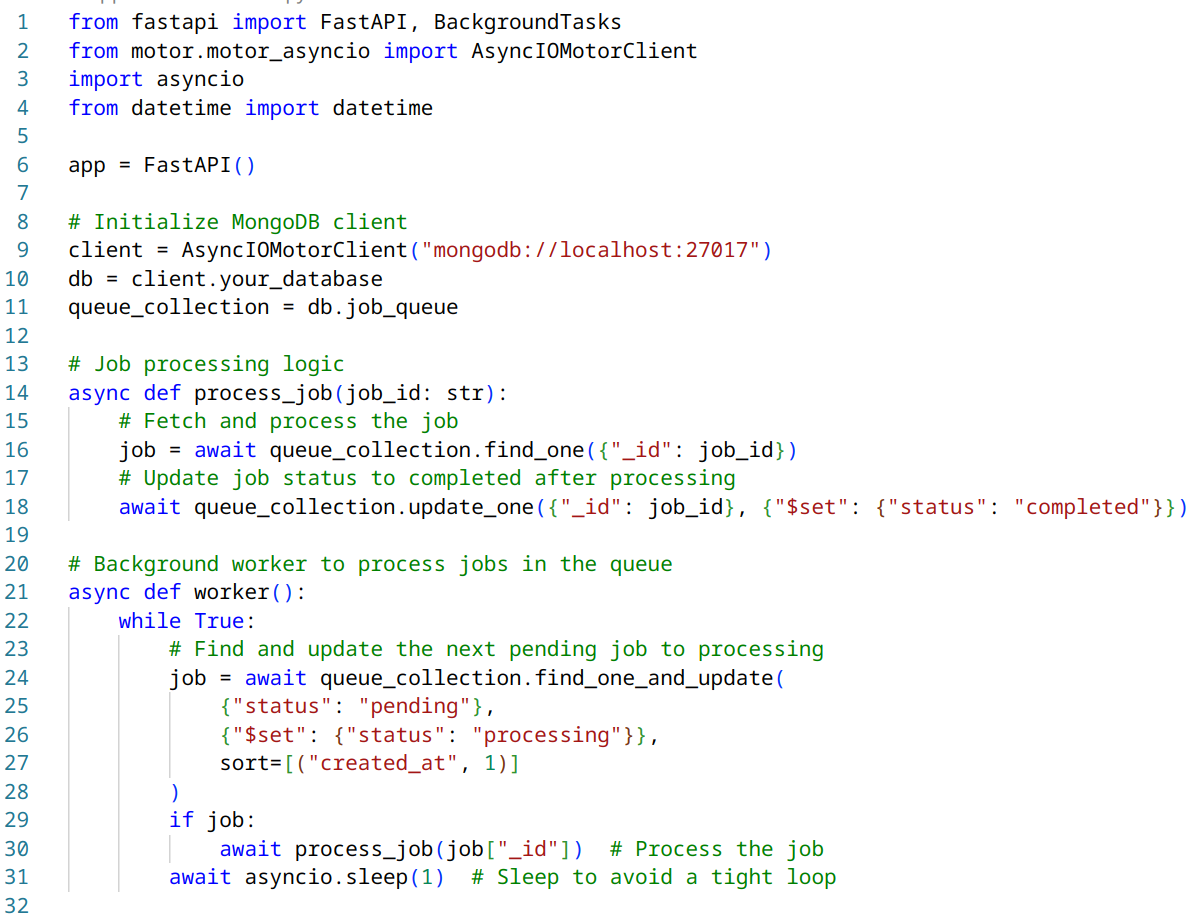
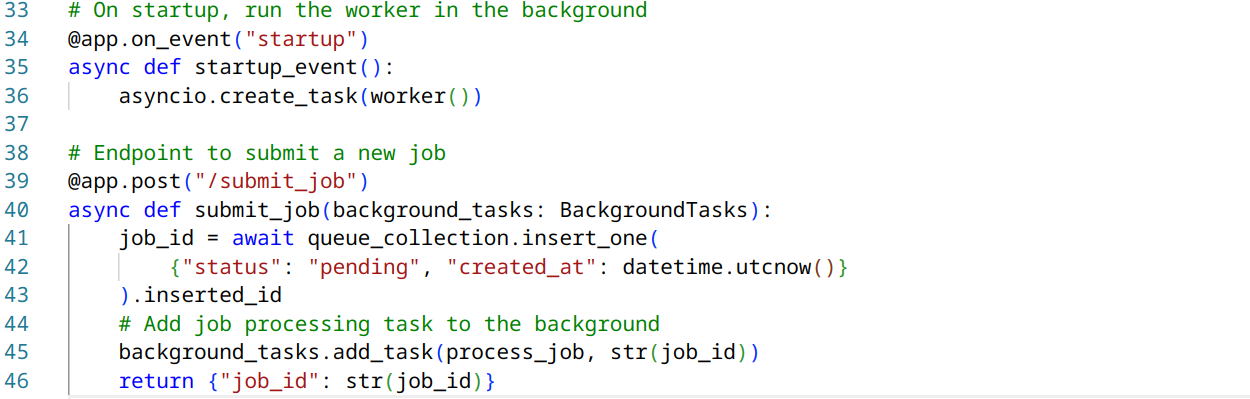
- Use FastAPI’s BackgroundTasks feature to queue jobs.
- Implement a worker coroutine that continuously checks the MongoDB queue for new jobs.
- Use asyncio to manage concurrent execution of background tasks.
Pros:
- Simpler setup, as it’s integrated within your FastAPI application.
- Easier to share resources and state with the main application.
Cons:
- May not scale as well for very long-running tasks.
- Could potentially impact the performance of your main API if not managed carefully.
- Harder to distribute across multiple processes or machines.
Here’s a basic implementation of the FastAPI (main.py):
Option 2: Separate Background Process
This approach involves creating a separate process or service to handle background jobs. Here’s how it could work:
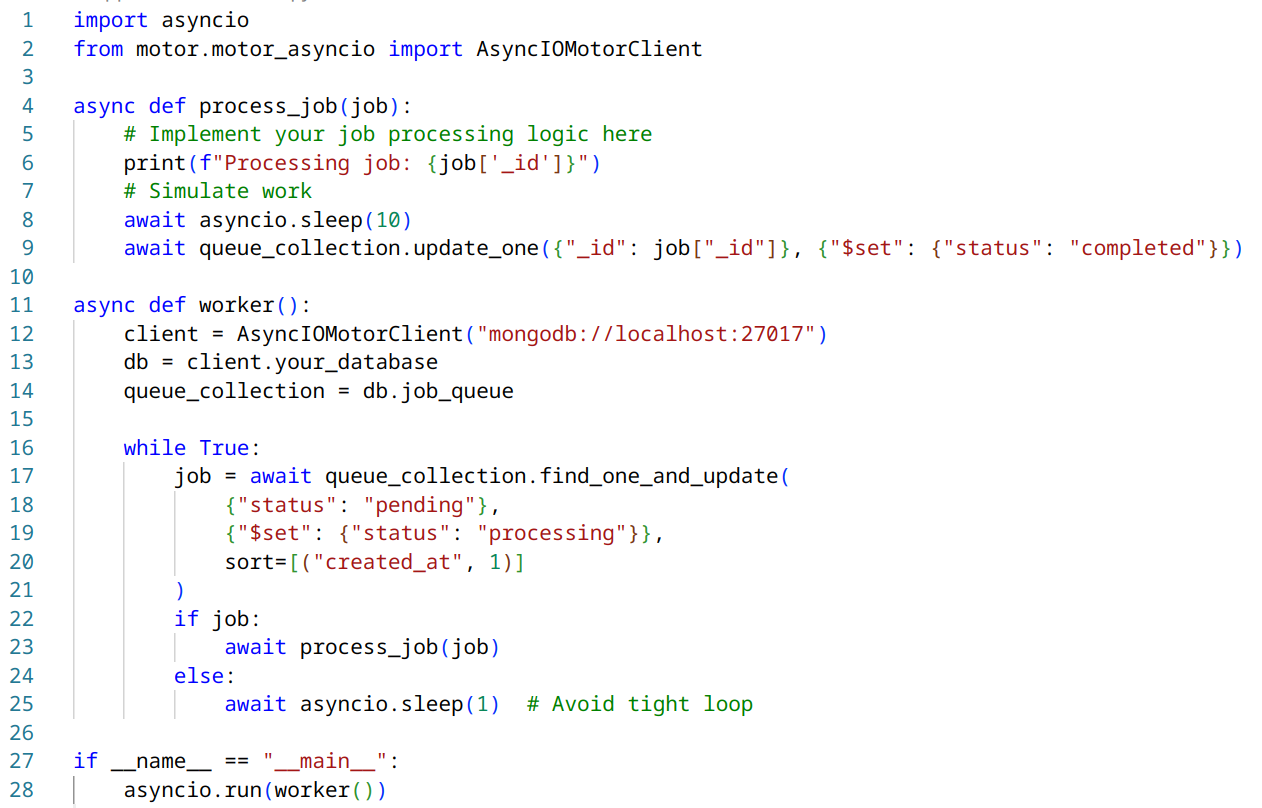
- Implement a separate Python script that acts as a worker process.
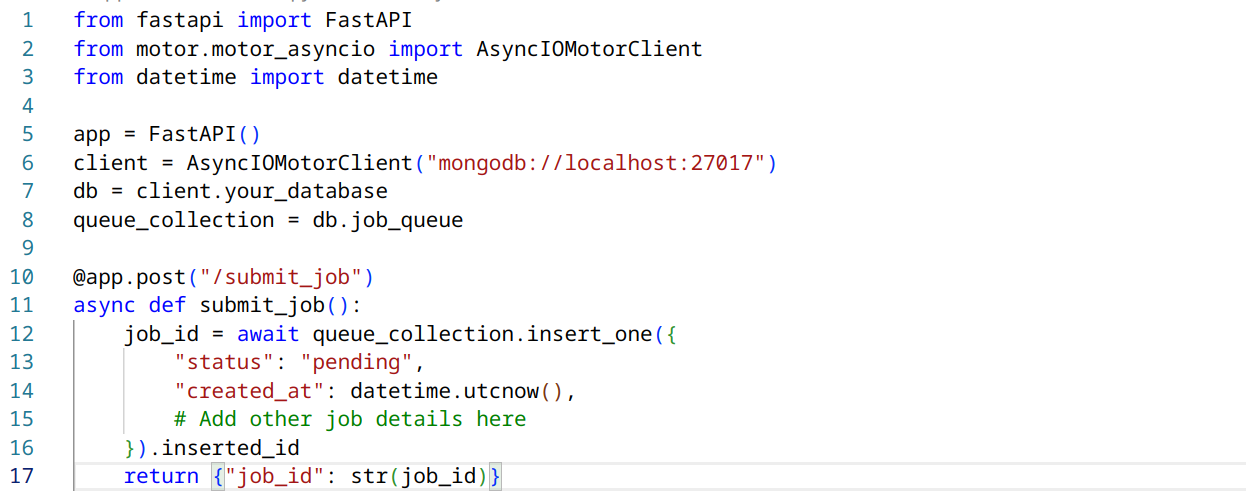
- Use a robust task queue system like Celery or RQ, or implement your own using MongoDB.
- The FastAPI application enqueues jobs, and the worker process(es) dequeue and process them.
Pros:
- Better isolation between API and background tasks.
- Easier to scale horizontally by adding more worker processes.
- Can be distributed across multiple machines more easily.
Cons:
- More complex setup and deployment.
- Requires additional infrastructure for task queue management.
Here’s a basic implementation using a custom worker process:
FastAPI application (main.py):
Worker process (worker.py):
To run this setup, you would start your FastAPI application as usual, and then start one or more worker processes using python worker.py.
Recommended Design
Given the requirements, especially the need to distribute across multiple processes when deployed to ECS or Kubernetes, it is best to pick Option 2: Separate Background Process.
This approach will give more flexibility in scaling and managing background jobs independently of your API service. It also aligns well with containerized deployments, where we can have separate containers for API and for workers.
To implement this:
- Use MongoDB queue as planned.
- Implement the worker process as shown above.
- When deploying, you can scale your API and worker containers independently based on load.
- Consider using a process manager like Supervisor or Docker’s built-in restart policies to ensure your worker processes stay running.
This approach will allows for handling long-running tasks like Textract processing without impacting your API performance, and it will scale well as the application grows.
Multiple Processes in Option 2
In Option 2, how would I set up multiple worker processes set up simultaneously? Will find_one_and_update() guarantee that only one worker picks up the job?
Yes, we can definitely have multiple worker processes set up simultaneously in Option 2. This is one of the key advantages of this approach, as it allows for better scalability and parallel processing of jobs.
The find_one_and_update() MongoDB API does indeed provide a level of guarantee that only one worker will pick up a specific job. This is because the operation is atomic, meaning it’s executed as a single, indivisible unit. Here’s how it works:
- The find_one_and_update() operation atomically finds a document matching the query criteria and updates it.
- If multiple workers are trying to get a job at the same time, only one will successfully update the document and receive it as a result.
- The others will get None (or null) as a result, indicating that no document was found matching the criteria (because it was already updated by another worker).
To set up multiple worker processes, you could:
- Run multiple instances of your worker script.
- Use a process manager like Supervisor to manage multiple worker processes.
- In a containerized environment (like ECS or Kubernetes), deploy multiple pods running the worker script.
Here’s an example of how you might modify the worker script to allow for easy scaling:
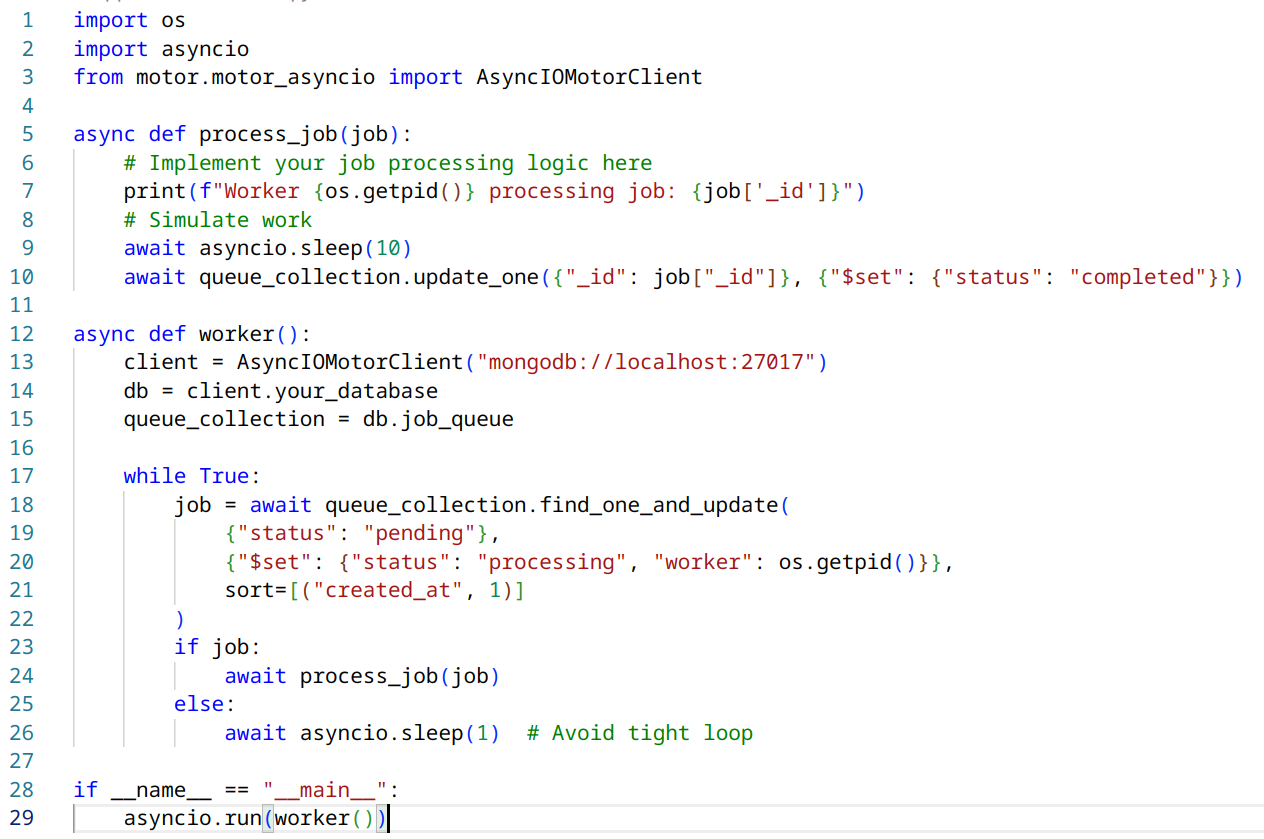
In this modified version:
- We’ve added a worker identifier (using the process ID) to the job document when it’s picked up. This can help with debugging and monitoring.
- The process_job function now prints which worker is processing the job.
You can run multiple instances of this script, and each will operate independently, picking up jobs as they become available. The find_one_and_update() operation ensures that each job is only processed by one worker, even when multiple workers are running simultaneously.
What if MongoDB has distributed readers?
Will find_one_and_update(), in that case, still be atomic? I am asking because MongoDB is not transactional, but an eventually consistent database.
1. Atomicity of find_one_and_update():
Even in a distributed MongoDB setup, find_one_and_update() is atomic at the document level. This means that for a single document, the operation is all-or-nothing and isolated from other operations.
2. Distributed readers:
In a distributed MongoDB setup with multiple replica sets, the primary node handles all write operations. Read operations can be distributed across secondary nodes, but write operations (including find_one_and_update()) are always routed to the primary.
3. Eventual consistency:
While MongoDB is eventually consistent across replica sets, the primary node always has the most up-to-date data. Since our find_one_and_update() operation is performed on the primary, we don’t need to worry about eventual consistency for this specific operation.
However, there are some considerations:
1. Network partitions: In rare cases of network partitions, there might be a brief period where a secondary node is incorrectly perceived as the primary. This could potentially lead to conflicting updates.
2. Rollbacks: If a primary node fails before replicating a write operation to a majority of the replica set, that operation might be rolled back when a new primary is elected.
To mitigate these issues and ensure stronger consistency, you can:
1. Use write concern: Specify a write concern that ensures the operation is acknowledged by a majority of replica set members before considering it complete.
2. Use transactions: For operations that span multiple documents or collections, you can use multi-document transactions (available in MongoDB 4.0+).
- Transactions, however, can only share session between the FastAPI and the background if the background is a coroutine in FastAPI (our Option 1)
Here’s how you might modify the worker function to incorporate these safeguards:
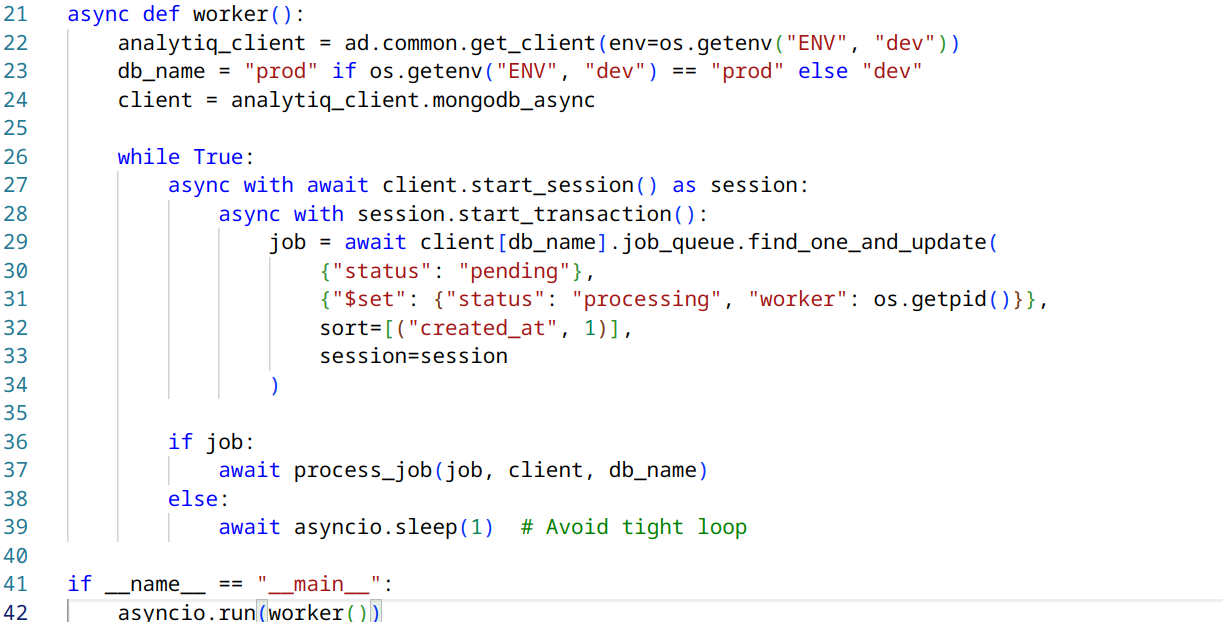
Be careful to not sleep() inside the transaction! The modification does a few things:
1. It sets the write concern to ‘majority’, ensuring that the update is acknowledged by a majority of replica set members.
2. It uses a session and transaction, which provides stronger consistency guarantees for the entire job processing operation. (
3. It passes the session to both the find_one_and_update() and process_job() functions, ensuring that all database operations within a job are part of the same transaction.
Remember to modify your process_job() function to accept and use the session:
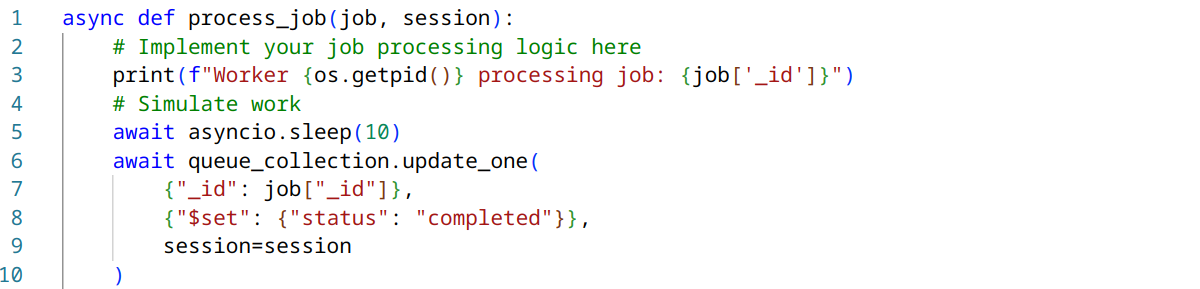
These changes will provide stronger consistency guarantees in a distributed MongoDB setup, minimizing the risk of job duplication or loss due to network issues or node failures.
The job, at any rate, should be implemented to be idempotent (meaning, if the job is called twice on the same message, the 2nd call should be a no-op).
Why should the job be idempotent?
It is very rare for the same message to be read by two workers. But, even if the queue was designed to guarantee single message delivery under any circumstance, it is still a good practice to design idempotent jobs. That way
1. If the sender is not idempotent, and requests the same job twice, the result is not duplicated.
2. If the job handler partially completes, e.g. due to a network error that causes an exception in the middle of the job – upon retry, an idempotent job should be designed to skip the steps it already completed, and only do the remaining steps.
(Code examples generated with Claude in the Cursor text editor.)
Comments? Suggestions? Alternatives?
I would appreciate your take on this!