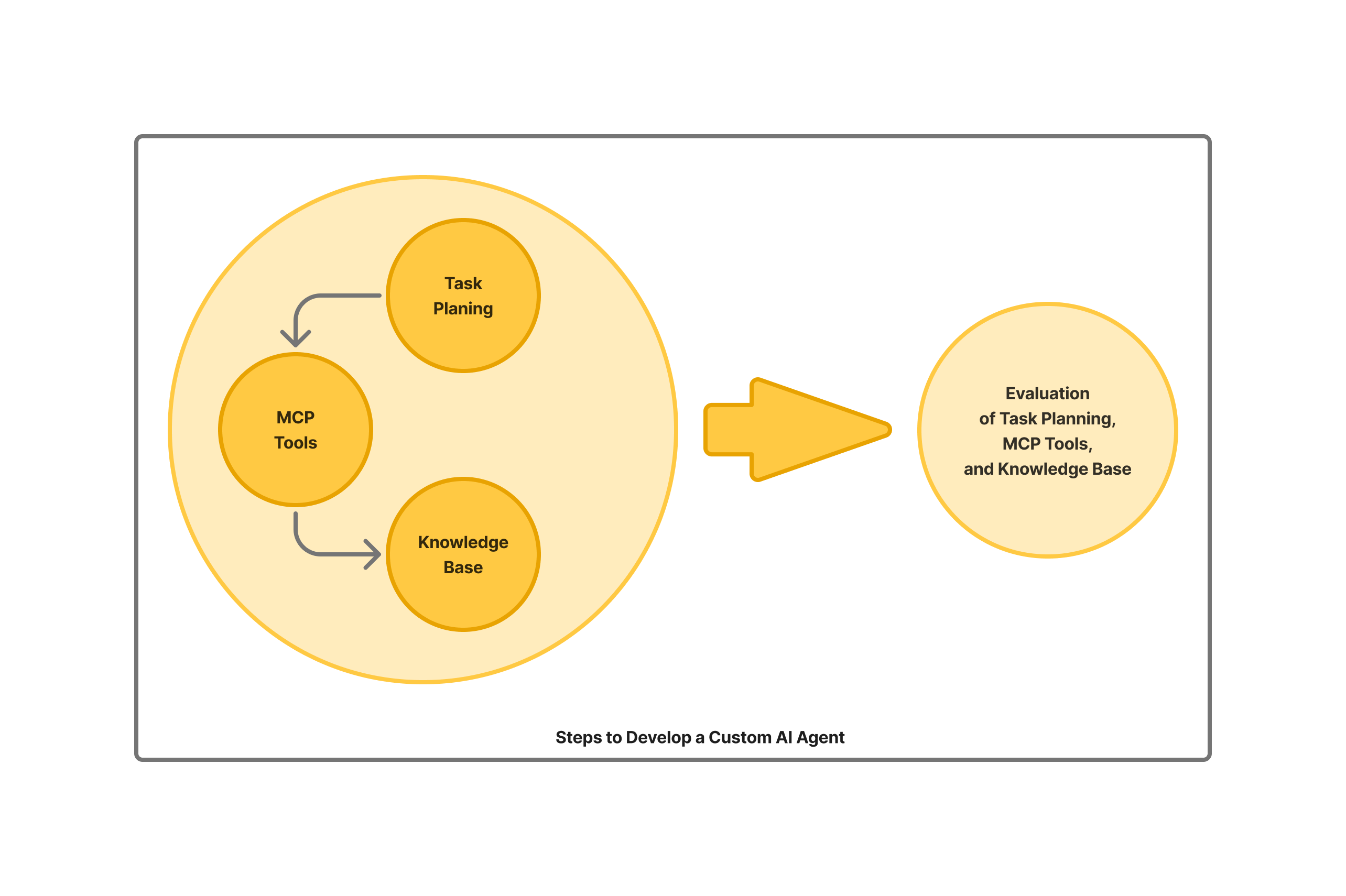
Developing an AI agent comes down to a number of intertwined yet distinct challenges:
- Create the runtime infrastructure for the agent itself
- Add tools for the task
- Planning: Making agent tackle the specific problem you’re aiming to solve
- Create a knowledge base the agent can use to inform its execution steps
- Set up an evaluation infrastructure to track progress and catch agent mistakes
- Integrate the agent into the larger application
Whether the AI agent is fully autonomous or works with human-in-the-loop oversight, development includes roughly the steps outlined above. Each step calls for its own set of techniques and tools.
Examples: Windsurf, Cursor and Claude Code
Let’s start with some examples the reader may be familiar with:
- AI Editors like Windsurf, Cursor, Github Copilot
- Command line tools like Claude Code.
The latter, Claude Code, also has a VSCode extension by the same name.
In each case, the underlying AI agents are integrated with the text editor (our Step 6).
While Windsurf, Cursor and Claude Code each have their own agent infrastructure (our Step 1), the latter, Claude Code is different in that it is available as a command line tool which can be executed standalone, in interactive or non-interactive mode.
Anthropic has also developed a Claude Agent SDK, with Typescript, Python and shell command flavors. The Claude Agent SDK can be used both for coding tasks and for more general tasks - for example, for document processing, or for support message processing, or for marketing research and outreach.
An Agent SDK is not available for Windsurf or Claude Code.
The knowledge base (Step 3) for these agents is embedded into the language models themselves. These coding agents can code in Python, Typescript, C, C++ or Java. The language models are trained on these programming languages.
While these agents do not technically require an external knowledge base for pure coding skills, they use a web search tool to look up product and API documentation. The web search tool comes handy when implementing coding tasks against specific coding libraries and APIs.
Windsurf, Cursor, Github Copilot use multiple-vendor language models, in addition to models used in-house. Claude Code on the other hand, only uses Anthropic language models.
Custom AI Agents, though, don’t have all necessary knowledge baked into their LLM model - and often need an external knowledge base, adapted to their task (Step 3).
For example - one of our customer companies develops a lab information management system that uses a scripting language to define web forms. The forms are used to manage lab processes in Biotech, Food Manufacturing, or Forensics. The AI Agent we developed employs an external knowledge base to provide full documentation and examples for the scripting language. The generalist LLMs, while trained on Python, Typescript and other programming languages, would not have baked-in information about the custom scripting language for web forms.
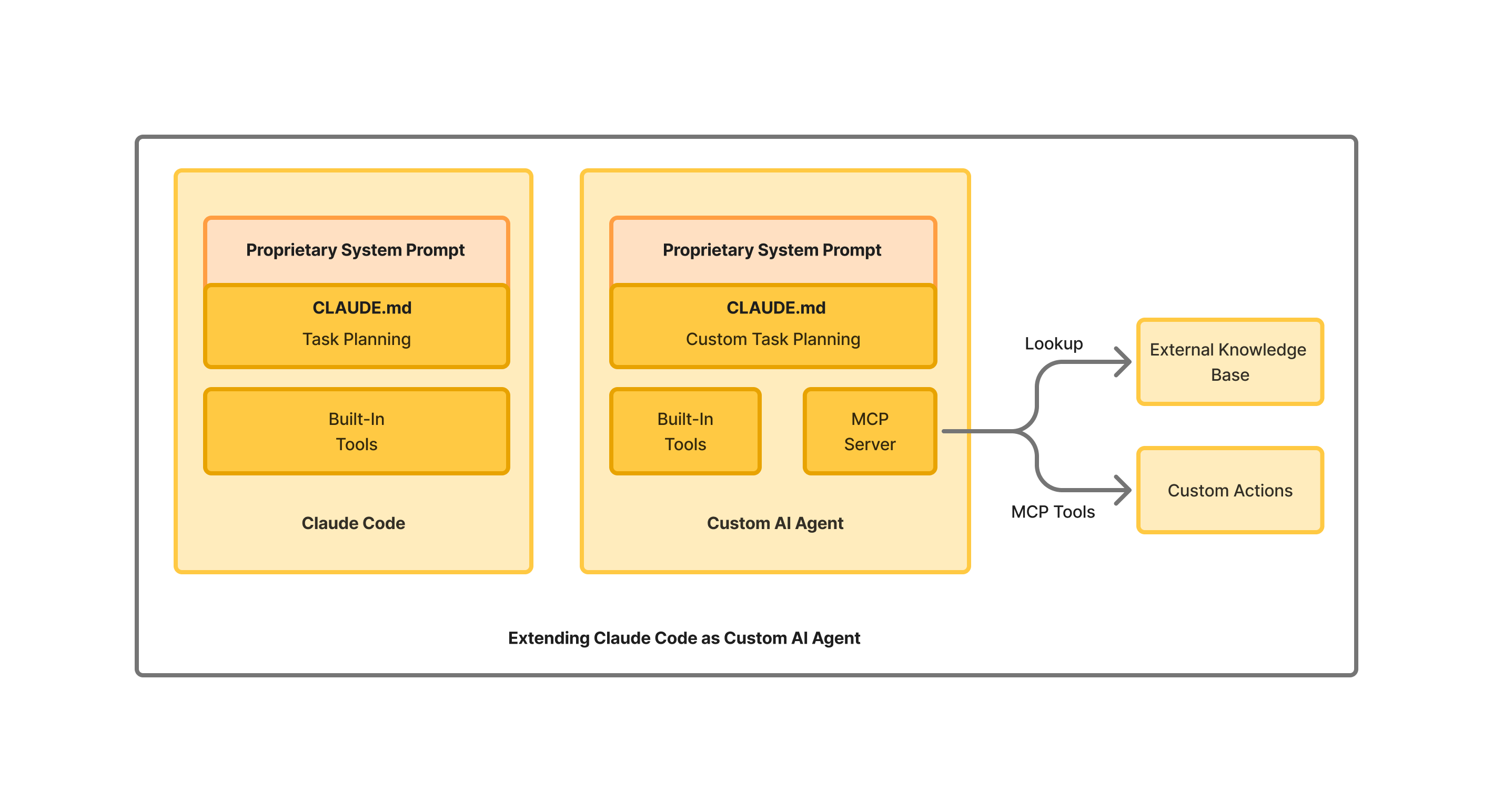
Custom AI agents need to implement their own external knowledge base and problem-solving tools. These are both integrated into the Agent using an MCP Server.
MCP support is already available in all AI Editors. The editors can act as MCP Clients, and can, for example, read external Github repositories through a Github MCP Server. Any MCP Server is supported.
An MCP Server, thus, can be used to make your AI agent act on your specific tasks, and to access your external knowledge base.
But having the tools and the knowledge base is not sufficient. The agent must also be steered through task planning (our Step 4).
The approach each of the AI editors takes to steer their coding task is proprietary, and slightly different. A lot of the steering is done through proprietary system prompts. Some have reverse engineered these system prompts through intercepting API calls - but, for the most part, they remain hidden.
Each AI editor, however, supports extending the system prompt through a configuration file: CLAUDE.md for Claude Code, Cursor Rules for Cursor,Windsurf Rules for Windsurf. It is these configuration files - CLAUDE.md in particular - that will be used to steer our Custom AI Agent.
Windsurf, Cursor, Github Copilot also use a tab-completion model, which employs a smaller, faster LLM acting directly in the editor buffer. Claude Code does not have that feature.
Evaluation for these AI editors is also proprietary (Step 5). Custom AI Agents would need their own evaluation infrastructure developed from scratch.
Here is a Comparison Table for the AI editors we described:
| Step | Windsurf, Cursor, Github Copilot | Claude Code | Custom Agent |
|---|---|---|---|
| 1. Runtime Infrastructure | Proprietary, integrated with text editors | Proprietary, available as command-line tool + VSCode extension | Claude Code + Claude Agent SDK (TypeScript/Python/Shell) |
| 2. Task Planning | Proprietary system prompt. Windsurf Rules file for Windsurf. Cursor Rules file for Cursor | Proprietary system prompt. CLAUDE.md for custom planning. | Custom via CLAUDE.md + editable system prompts (Claude Agent SDK) |
| 3. Knowledge Base | Embedded in LLM training + web search for API docs. Extensible through MCP. | Embedded in LLM training + web search for API docs. Extensible through MCP. | External vector DB (Pinecone/Weaviate/Qdrant) + custom MCP server tools |
| 4. Evaluation Infrastructure | Proprietary, internal evaluation systems | Proprietary, internal evaluation systems | Custom evaluation scripts + LLM Judge + web visualization dashboard |
| 5. Integration | Native text editor integration | Command-line + VSCode extension | Custom VSCode extension |
Separation of concerns: Infrastructure vs. Task-Specific Planning
When it comes to building the agent, we separate out the Infrastructure design from the Task Planning, for a couple of reasons:
- Often times, the task solved by the agent needs to be flexible and can change in the product lifecycle. This calls for infrastructure to be separated out from the task customization. Sometimes, the task or its subtasks are not even fully known or understood at the outset of the AI Agent project.
- The infrastructure is now available ready-made, and may not have to be built from scratch.
Adopting a ready-made, battle tested AI Agent Infrastructure that is steerable for your task will accelerate your AI Agent design.
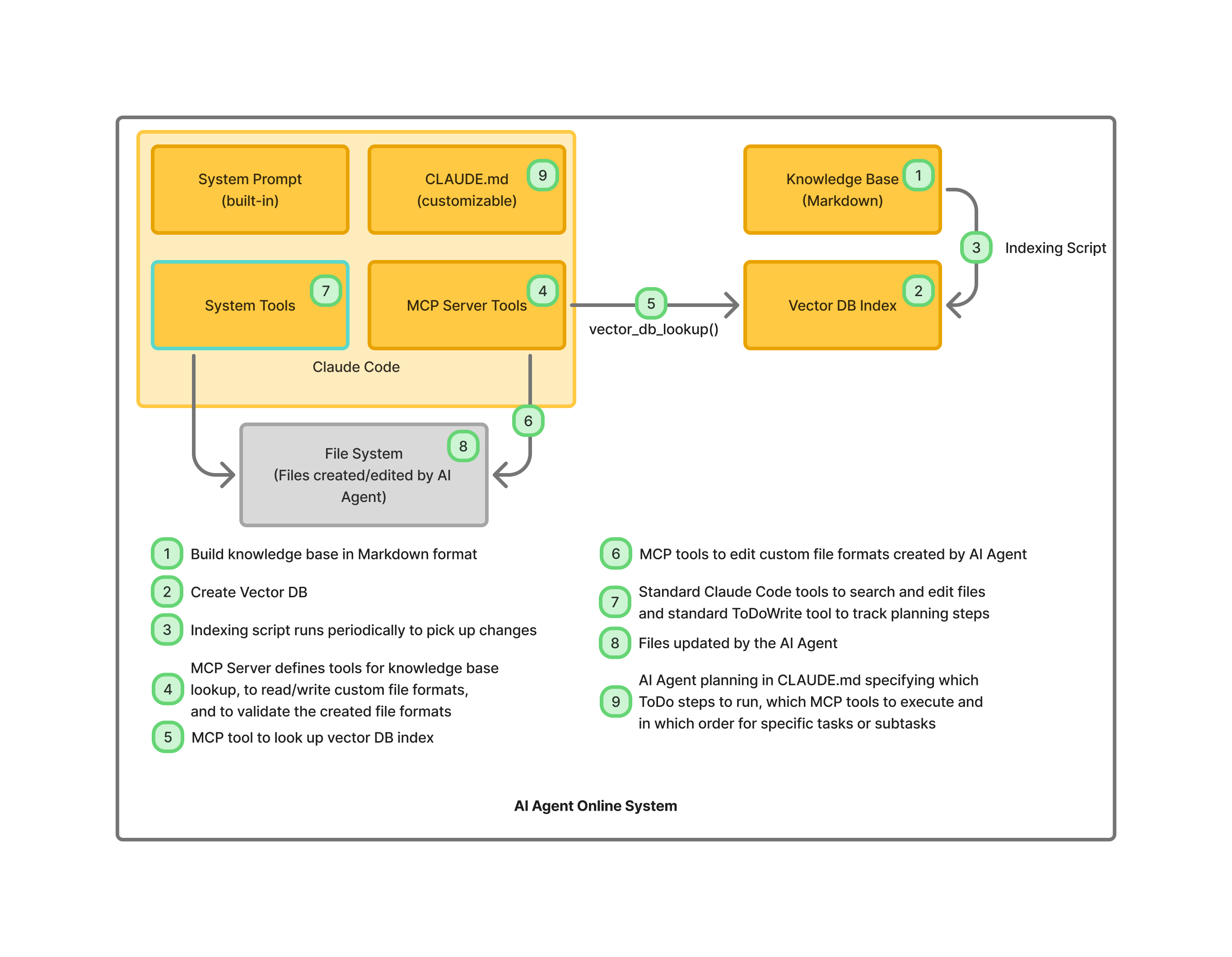
The AI Agent Infrastructure
As of this writing, our go-to stack for agent creation is the Claude Code shell command, complemented by the Claude Agent SDK. Its advantages:
- A suite of powerful features like CLAUDE.md customization, subcommands for modular execution, subagents for hierarchical delegation
- MCP server support, which lets you seamlessly extend the agent, and steer it to solve the task at hand.
- Built-in prompt caching, and discounted packaged price for utilization, when using a Claude subscription.
No agent is complete without a solid knowledge base, and without good evaluation infrastructure.
The Claude Agent SDK doesn’t ship with either out of the box. You’ll need to craft them yourself.
For the vector database powering the knowledge base, we’ve used Pinecone, prized for its straightforward SaaS model that gets you up and running quick. Pinecone documentation is also very accessible.
That said, there are multiple Vector DB alternatives: Weaviate, Qdrant, or ChromaDB. Even traditional players like Postgres or MongoDB have jumped on the vector bandwagon, now offering built-in support for vector tables or collections.
In our architecture, we centralize all custom interfaces for the agent within the MCP server. This ensures portability and testability across setups. The MCP server includes a vector_db_lookup() interface to let the agent look up the knowledge base.
Indexing Your Knowledge Base
To build the knowledge base, you need:
- A collection of knowledge base files - we usually convert them all to Markdown, and store them in an S3 bucket, or in a MongoDB collection
- A vector DB index in your DB of choice
- An indexing script, that runs periodically, and uploads the knowledge base markdown files into the vector DB index, mapped through an LLM embedding.
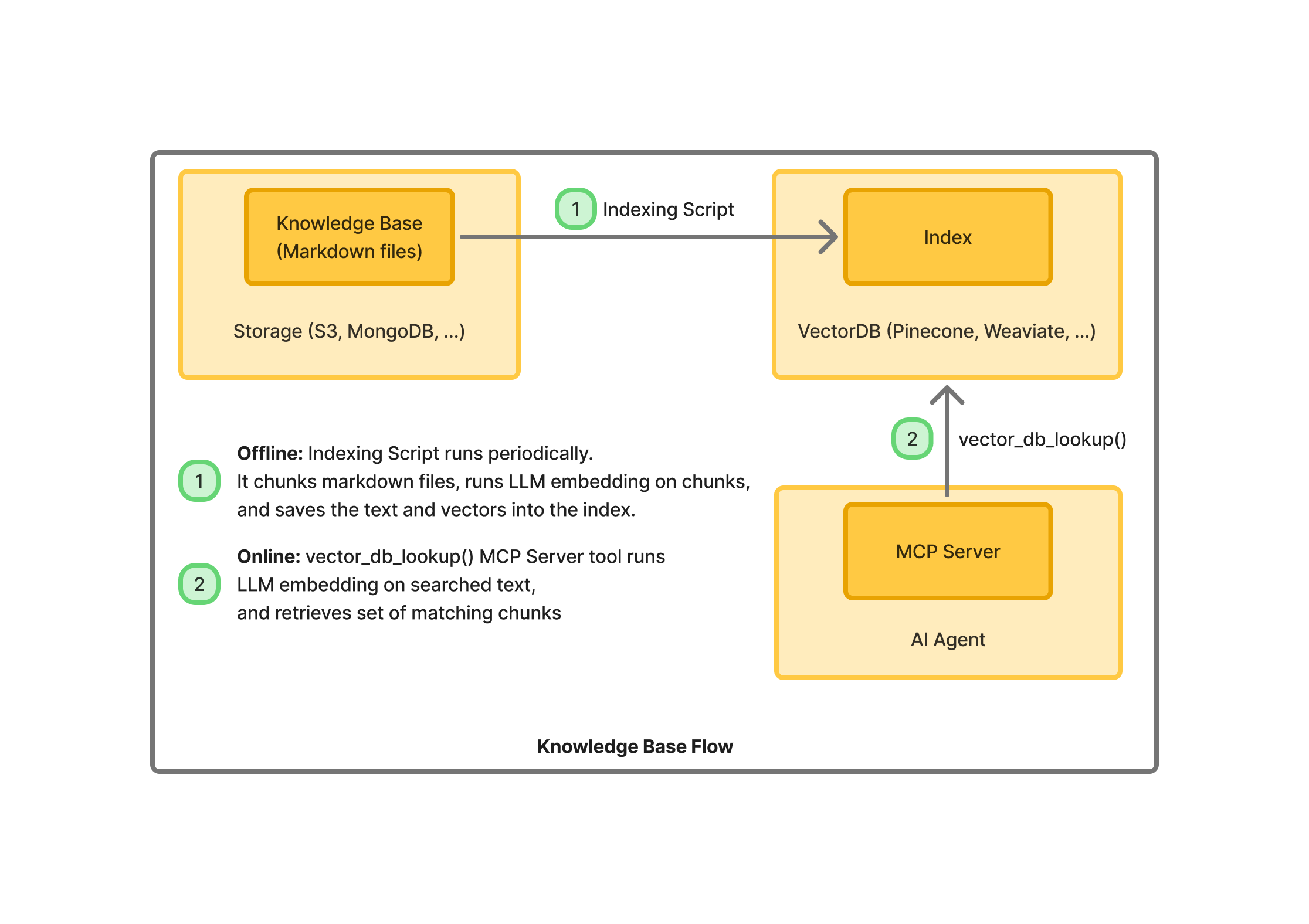
The lookup operation is what you’d expect - the searched text is mapped through the same LLM embedding, and looked up for similarity with existing chunks in the vector db index - returning the most closely similar chunks from the knowledge base.
Tuning AI Agent Actions via the MCP Server
With the knowledge base available, and searchable - we now let the AI agent use it through MCP Server tools.
These tools can:
- Look up knowledge base articles for similarity
- Perform file reads and edits that are specialised to your file format
- Validate file edits, and run unit tests
The tools take parameters, and are self-describing. The LLM model can figure out, to a good extent, which tools to call, and which parameters to pass - however, that is not sufficient for good agent design, because:
- The same operation may be solved by different tools.
- Or, the tools need to be called in a certain order.
This is why step is crucial: Task Planning, which steers the agent in how it uses the MCP Server tools.
Task Planning
Task planning is designed partly through editing CLAUDE.md, and partly through changing the system prompt.
- With the command-line Claude Code tool, its internal system prompt is not editable.
- But with Claude Agent SDK, it is.
In CLAUDE.md, we specify how to approach the various custom problems the agent might encounter. Claude Code has built-in support for the ToDoWrite tool. In CLAUDE.md, we specify what are the ToDo tasks, for each problem the AI Agent might encounter.
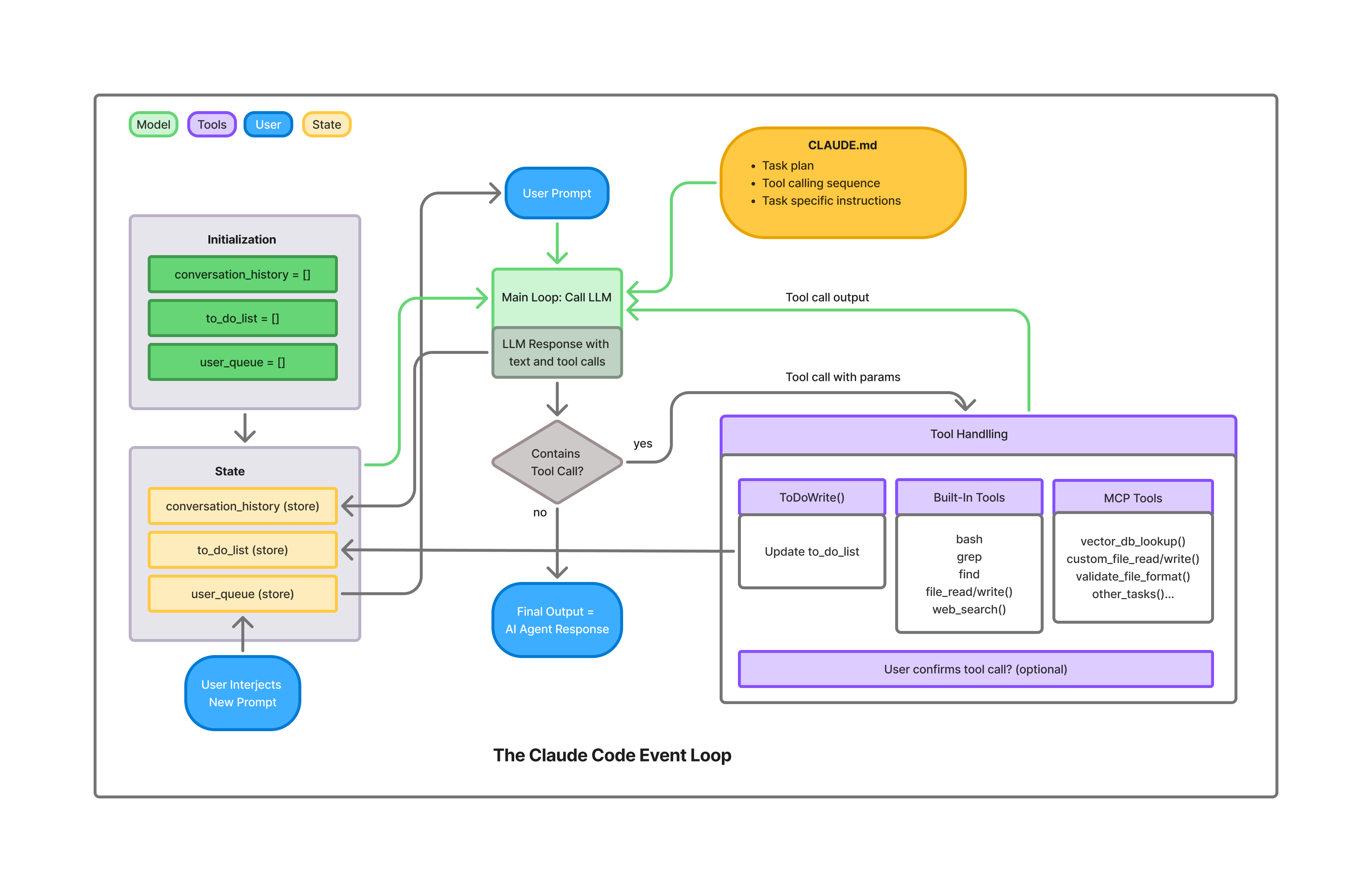
The Claude Code Event Loop
The Claude Code agent itself has a baked-in event loop, which takes user input, file attachments and screenshots - puts CLAUDE.md in context, determines its ToDo tasks, and iterates through MCP Server tools and other built-in tools to solve the task.
The user can interrupt the flow at any moment, and continue it with altered instructions.
From there, the agent marches forward, step by step. It can go solo or pause for human nods, calling on more MCP and built-in tools as needed to create new files, edit existing ones, or query the knowledge base.
Tuning the Agent through Evaluation
Once the infrastructure is stood up, the knowledge base available, the MCP server working, and the agent begins to be integrated in the larger application - you need to tune the agent and adapt it to the task at hand.
Tuning can mean:
- Adding or updating to the knowledge base
- Adding or updating the MCP server tools
- Improving the CLAUDE.md design, to steer the running agent through its __ToDo__s.
Evaluation is an essential step here.
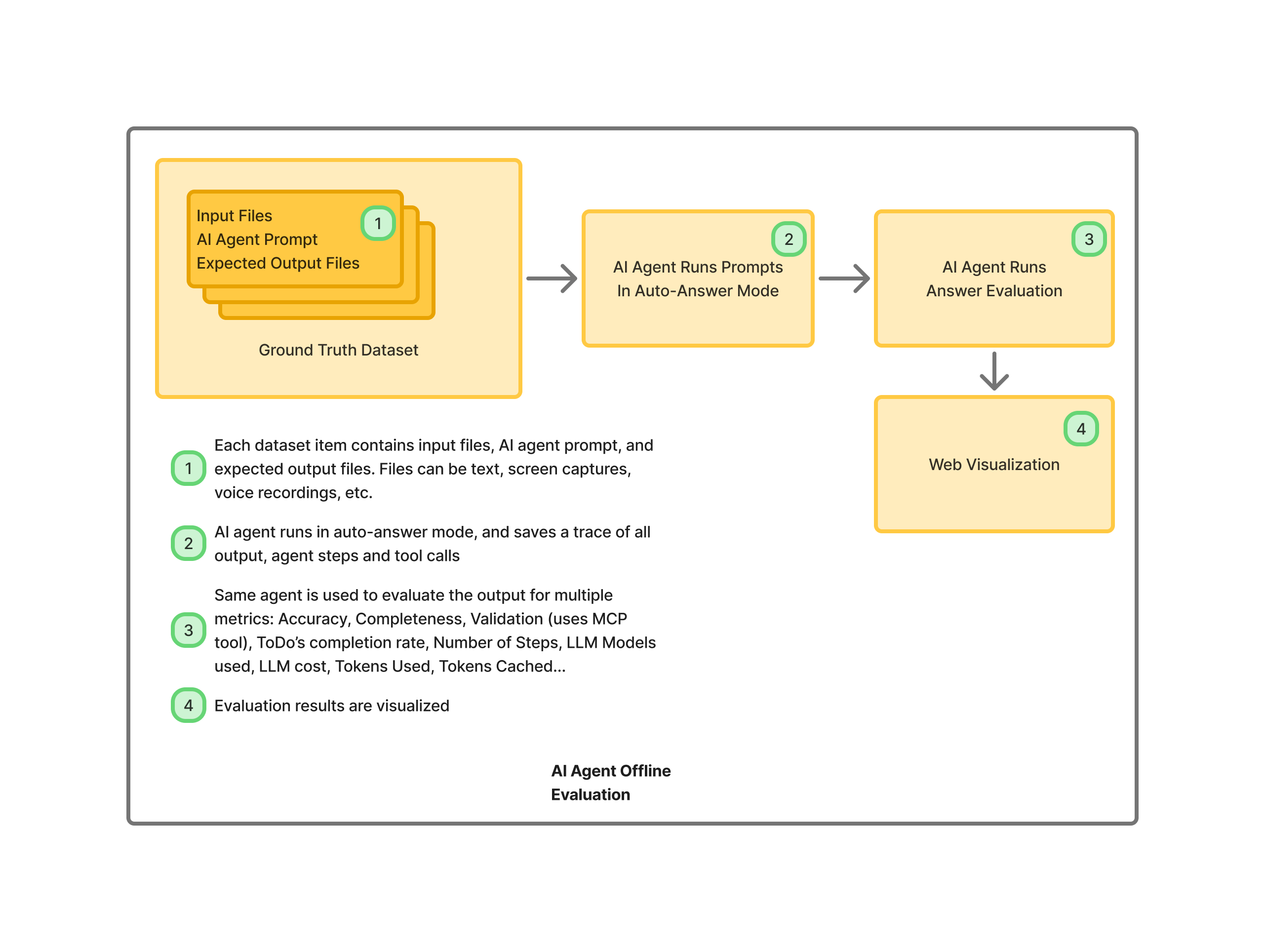
Kick things off by:
- Assembling a ground-truth dataset — a curated set of benchmark problems mirroring real-world scenarios.
- Create an evaluation script that, for each item, spins up a fresh Claude Code instance to tackle the problem in pure automated mode, assuming no user intervention.
- Once the _Claude Code instance completes processing a dataset item, a second forked instance of Claude Code runs to evaluate and judge the output, for a number of metrics, as LLM Judge.
The metrics tracked by the LLM Judge are:
- Accuracy: How spot-on are the results?
- Completeness: Does it cover all requirements without omissions?
- For MCP interfaces leaning on vector DB retrieval: Accuracy and completeness of the chunks pulled back.
- Completion rate of the ToDo’s
- Drilling deeper, for select MCP tools: Per-tool breakdowns of response accuracy and completeness.
- Number of failed validations during the actual run
- Validation tests run by the LLM judge at eval time, using the same MCP validation tools you added
- Other statistics: number of steps to solve the question, LLM models used, in and out tokens, cached tokens, cost
Bringing Eval to Life: Visualization
Raw eval logs are hard to monitor without an at-a-glance view.
In our approach, we build a custom web visualiser of eval results, with:
- A quick-scan table, one row per question, for instant overviews.
- A radar chart aggregating metrics into a visual story of strengths and gaps.
- Distributions to reveal patterns across the board.
- Per-question deep dives on tool usage: At-a-glance summaries of which tools fired, what inputs they took, the outputs they spat, and any ToDo progress where relevant.
Iteration and Improvement
Here’s how the development loop flows in practice:
- Bootstrap your ground-truth dataset with questions to get baseline momentum.
- Start the evaluation suite and scrutinize the metrics
- For each metrics shortfall, triage the root cause:
- Does the knowledge base require new or updated data?
- Is the problem caused by Vector DB chunking, indexing, or retrieval?
- Is an MCP tool not working properly? Or is a new MCP tool needed?
- Or perhaps CLAUDE.md itself needs a refresh to better guide the agent?
As problems are discovered, and fixed, the ground truth dataset is expanded. Re-running over previously-working dataset items ensures the new fixes don’t break old functionality.